När vi planerade vilka metoder vi skulle använda i researcharbetet i projektet insåg vi snabbt att vi behövde veta varför projektet initierats; vilka mål och visioner fanns? Tankar om komplexa spörsmål? Policyfrågor? Förutom en intervju med initierande chef skulle en fokusgrupp med bibliotekets ledningsgrupp kunna hjälpa oss.
Fokusgrupp som metod är ofta ifrågasatt
Kritiken går ut på att man inte kan fånga upp egentliga behov och beteenden, bara vad gruppen säger sig tycka. Att någon lätt dominerar hela diskussionen och gruppen tenderar att följa den personen och eftersträva koncensus istället för att uttrycka individuella motiv. Fokusgrupp används ofta vid marknadsundersökningar där man vill veta hur man förstår och pratar om en speciell produkt. När man använder metoden ska man göra det för att få insikt i tankegångar och attityder, inte för att hitta sanningar.
Fokusgrupp blir workshop?
Nu är ju ledningsgruppen inte de användare vi designar webben för, så deras beteende behövde vi inte bry oss om. Övriga fokusgruppsfällor försökte vi parera genom att göra en workshopsliknande fokusgrupp och med explicit uppmaning att inte tänka koncensus. Det ger projektet mycket mer om vi kan få många infallsvinklar, olika sätt att tänka och få till stånd riktigt bra diskussioner till komplexa frågor. Koncensusönskande grupper tenderar att skyla över problem och olikheter. Vi tror att det också gav ledningsgruppen en djupare förståelse för olika frågeställningar och vad man behöver brottas med.
Skalor och prioriteringar
Ledningsgruppen fick arbeta mycket med skalor och prioriteringar där inget fick vara lika viktigt. Resultatet var inte det viktigaste utan att man tvingades resonera, argumentera och tänka om under arbetets gång.
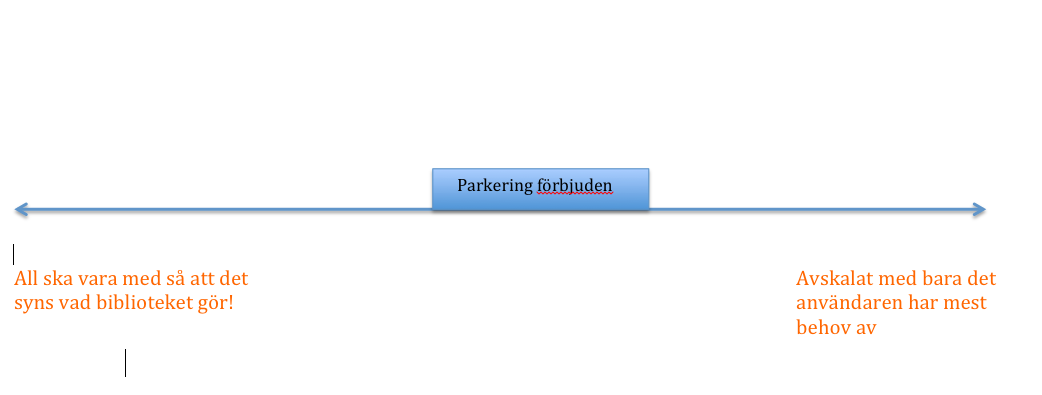
Uppgift: Var sätter du dig på den här skalan? Mitten är förbjuden parkering så du måste ta ställning. Berätta hur du tänker när du placerar dig där.
Exempel på ”skaluppgifter”
Allt som biblioteket gör måste med så att det syns vad vi gör vs. Avskalat gränssnitt som hjälper användaren att lösa en uppgift
Personalens tillgänglighet vs. Fixa själv
(t.ex nå någon hela tiden via en snabb och synlig kanal från samtliga sidor vs. Så mycket som möjligt ska finnas på webben så att vi kan hänvisa dit)
Prioritering som workshopsmetod
En annan uppgift var att varje person i ledningsgruppen fick berätta i vilken prioritetsordning de satte olika delar av webbarbetet. ”Vad är viktigast? Berätta hur ni tänker. Ni får ångra er när ni hör andra.” Återigen var det inte rangordningen som var det viktiga, utan det resonemang och de diskussioner det lockade/tvingade fram.
Saker de fick i uppgick att rangordna inom webbprojektet var t.ex.
det visuella intrycket
tilltalet i text och bild
att hitta och navigera lätt genom den uppgift användaren vill utföra
marknadsföra och presentera bibliotekets informationsresurser
marknadsföra och presentera bibliotekets ”fysiska verksamhet”
marknadsföra andra strategiska delar av verksamheten
….
Vem riktar vi oss mot?
Fokusgruppens diskussionen om vem vi riktade oss mot genom webbplatskanalen blev ett exempel på olika infallsvinklar som blev fruktbara. Diskussionen böljade från klassiska användarkategorier/målgrupper (studenter/lärare/forskare/tredje uppgiften) till att strunta i målgruppstänkandet och designa för ett beteende eller en uppgift.
Värdeord – vad ska webben signalera?
Ledningsgruppen hann dessutom med att ta fram 3 värdeord som de tycker webbplatsen ska uttrycka. Men vilka värdeord det blev berättar vi lite senare, i ett eget blogginlägg och när övrig bibliotekspersonal haft samma workshop!
Stort beröm beröm till bibliotekets ledningsgrupp som engagerat tog sin an uppgiften och gärna diskuterade saker som det inte finns några lätta svar på.
Startskottet har gått för projektet Ny webb för Chalmers bibliotek och ett intensivt researcharbete pågår. Inläsning, omvärldsbevakning och att prata (webbkonferera) med andra bibliotek som precis gjort samma resa är en naturlig inledning. Och att vi ska dokumentera och kommunicera bland annat via bloggen.
Men sedan – hur ska man närma sig projektet? Hur ska vi arbeta för att få en användbar webb? Vilka metoder ska vi använda? Hur bestämmer vi det?
Vad behöver vi veta för att genomdriva projektet?
Ett enkelt och bra sätt att ringa in arbetet är en workshop där projektgruppen tar fram alla frågor vi behöver ha svar på för att lyckas med projektet. Gruppera och skriva om till nyckelfrågor som vi kan ha med som stöd och stämma av mot under arbetet. En stor vinst är att alla får en gemensam bild av projektet.
Frågorna blir underlaget när vi väljer metoder och vem vi behöver fråga för att få svar.
Utifrån vår frågebrainstorming utkristalliserade sig några metoder för researcharbetet:
Mål, policies & visioner
– intervju med uppdragsgivande chef
– fokusgrupp – ledningsgruppen
– intervju med Chalmers centrala kommunikation
Vem använder idag? Vad används?
– gräva i statistik, analytics m.m.
Lär känna användaren
– etnografiska intervjuer/observation som ska resultera i personas och scenarier
– workshop med personalen
Utformandedelen sparar vi till vi har fått svar på våra frågor.
Anna Johansson går sitt andra år på B & I- utbildningen vid Linnéuniversitetet i Växjö och hade sin verksamhetsförlagda utbildning (praktik) på Chalmers bibliotek under v. 42.
Under denna praktikvecka har jag studerat bibliotekets webbresurser. Mestadels var jag på avdelningen för Informationsresurser och Tillgängliggörande, men fick även chansen att vara på avdelningen för Publiceringsservice och Bibliometri och se deras funktioner och arbetsuppgifter.
Jag fick introduktion till bibliotekssystemet, hur fjärrlåneverksamheten går till, vilka sociala medier som används, fått en liten inblick i vilka databaser som biblioteket erbjuder och hur bibliotekskatalogen fungerar. När jag var på Publicerings- serice och Bibliometri fick jag prova på att registrera artiklar i CPL. Jag upptäckte att det var många saker som man ska hålla reda på och många steg att gå igenom för registreringen, men jag tyckte att det var roligt och intressant. Publicering och Open Access blir alltmer aktuellt och det är troligt att jag kommer få arbeta med dessa saker på något sätt i framtiden och det är en fördel att jag har fått prova på det eftersom databaserna ser ungefär likadana ut i grunden och har i stort sett samma principer för hur man jobbar med dem.
Sista dagen på praktikveckan var jag på ett användargruppsmöte om Summon på Högskolan i Borås. Tidigare i veckan hade jag fått lite insikt om Summon så mötet var inte helt oförståeligt för min del. Jag fick ta del av hur lärosätena som medverkade hade implementerat och lanserat Summon och vilka framtidsplaner de hade och hur de vill att tjänsten ska utvecklas anpassad för användarna.
Sammanfattningsvis har denna praktikvecka på Chalmers bibliotek varit mycket intressant och lärorik. Jag har blivit mycket bra bemött av alla som jag träffat och arbetat tillsammans med. Jag har fått en väldigt bra inblick i de olika funktionerna på de två avdelningar jag var på. Jag fick introduktioner till avdelningarnas arbetsuppgifter och fick arbeta lite praktiskt genom att regsistrera artiklar i CPL och vara med i informations- disken. Jag är mycket nöjd med min vecka här och jag kommer ta med mig dessa kunskaper på framtida arbeten.
En torsdag för inte alltför längesedan gjorde vi en workshop i designmetodik med intresserad personal på Chalmers bibliotek. Och det var glädjande många. 30 stycken deltog och fick vara med om en designresa i expressfart. Från en första definitionen av vad designprocessen kan innebära till att skapa en pappersprototyp som gick att testa. En inte minst viktig bieffekt av eftermiddagen var att ha roligt tillsammans!
Workshopen leddes av Johan Ahrén från Libris, Kungliga biblioteket och Kristin Olofsson, Chalmers och var en repris av den designworkshop som hölls under Libris inspirationsdagar 2010. Det är tack vare Johanna Olander (interaktionsdesigner på Libris) som har delat med sig av sina kunskaper och har inspirerat oss till att tänka design och användarbehov på ett djupare sätt.
Lära från UX-världen
Mycket av innehållet har hämtats från interaktionsdesigns- och UX-världen (user experience). Därifrån kan vi på biblioteken hämta mycket kunskap om användararbete; förhållningssätt, metoder & verktyg. Workshopen började med att konstatera att i UX-världen är design inte detsamma som form och färg. Design är istället hela den process som handlar om att ta fram en tjänst eller produkt som är meningsfull och skapar ett mervärde för en användare.
Vad är design – egentligen?
Vi pratade om design som kunde bestå av en process som innehåller
• strategi (är det det här vi ska göra?)
• research (lär känna användaren, hennes behov och motivationer)
• informationsarkitektur (hur man strukturerar innehållet)
• interaktionsdesign (ta fram produkter som är självklara att förstå och interagera med)
• visuell/grafisk design (stödja interaktionen och förmedla rätt känsla)
Vi blandade mer teoretiska avsnitt av metodgenomgångar och synsätt med praktiska övningar. Betoningen låg på användarresearch (lär känna dina användare) och lite interaktionsdesign.
Deltagarna fick prova på att göra intervjuer. Konsten att ställa bra frågor och vad man ska fånga upp från den intervjuade. Nu gällde det att ringa in någon slags beställningsfunktion som användaren hade behov av.
Idégenerering
Så provade vi en idégenereringsmetod. Skissa/skriv/klipp till idéer till beställningsfunktionen och det ska härstamma från det man fick fram på intervjuerna. Cirkelteknik – i det här fallet fick alla gå ett varv runt bordet för att inspireras av andras skisser – är en metod som går att variera i det oändliga.
Prototypande – light
Sedan var det dags att ta fram en enkel pappersprototyp, men en prototyp som beskrev ett flöde som skulle vara testbart. Grupperna fick samarbeta om en prototyp och fick sedan feedback på sitt arbete när en testperson från en annan grupp kom och testade idén och användbarheten.
Så kan man iterera research -> idégenerering -> utvärderig tills man får en tjänst som är meningsfull och användbar. (från Johanna Olander)
Det här kan nog bli ett bra avstamp till det projekt om en ny webbplats för Chalmers bibliotek som ligger i startgroparna!
Den 24-27 maj hade jag nöjet att delta i European Library Automation Groups årliga konferens som hölls på National Technical Library i Prag. En riktigt läcker, stor och modern byggnad. Gillade särskilt det fyndiga ”klottret” på balkonger och trappor.
Temat för konferensen var ”It’s the context, stupid!” och de mest förekommande begreppen var Linked data, Open Data och ”The Cloud”. Deltagarna var främst system- och metadatabibliotekarier samt IT och webbpersoner. Ett bra inslag var workshoparna. Fyra av konferensens sessioner ägnades åt djupdykning inom ett av tio möjliga ämnen där deltagarna aktivt skulle delta.
Förutom möten med människor som arbetar med samma eller relaterade frågor tog jag framför allt med mig tankar om:
• Vikten av att verkligen förstå de avtal vi ingår i. Inte minst med tanke på den nya struktur som ”nästa generations” molnbaserade bibliotekssystem innebär.
• Möjligheterna som länkad data öppnar med kopplingar mellan data och läckra visuella navigeringar. Lust att använda RDF och RDFa på den data vi hanterar.
• Att vi, när vi designar vårt digitala bibliotek, lyfter blicken från våra samlingar och fokuserar på vad våra användare behöver och kan tänkas uppskatta. Glöm inte användarstudierna.
• Att anpassa den fysiska biblioteksmiljö till en teknikintensiv interaktiv och trivsam miljö för kreativa studenter.
Keynote “Blended libraries”
Harald Reiterer (professor på Computer and Information Science Department vid University of Konstanz) http://hci.uni-konstanz.de/
Reiters forskargrupp undersöker användargränssnitt och interaktion mellan människa och dator i biblioteksmiljö. Vi fick en fullt möjligt blick in i en (nära?) förestående framtid med avancerad intuitiv teknik helt integrerad i den fysiska biblioteksmiljön. Ett ”blended library” som utgår från studenternas behov att studera och interagera med varandra och det material som biblioteket och omvärlden tillhandahåller.
Forskargruppen jobbar med att studera hur kooperativ sökning fungerar och uppfattas. Tekniken går ut på studenter tillsammans på ett gemensamt stort touchdatorbord använder facettsökning visuellt för att nå fram till en gemensam slutsats. Trots att tekniken var helt ny för testpersonerna låg fokus på innehållet och den booelska logiken bakom upplevdes som begriplig.
Länkad data
Flera av sessionerna handlade om mer eller mindre långt gångna projekt med länkad data. Kort handlar länkad data om att använda URIer för som identifikatorer och beskriva data och dess relationer med specifika vokabulärer och standarder. Allt för att datat ska bli maskinläsbart och kunna användas av andra applikationer. Och för att kunna användas ska det givetvis även vara fritt tillgängligt.
Flera beskrev hanteringen av vokabulärer som en av svårigheterna med att få till stånd otvetydiga länkar, t. ex Jane and Adrian Stevenson som jobbat med att få ihop biblioteksdata med arkivdata i LOCAH-projektet http://blogs.ukoln.ac.uk/locah/ och universitetsbiblioteket i Amsterdam som jobbar med att integrera information från teaterinstitutets databas med bibliotekets katalog.
Metadatats kvalitet är a och o för att få länkad data att fungera. Ordning, reda, konsekvens och tydlighet! Auktoritetsposternas lov sjöngs och behovet av smart matchning för att överbygga problem som grundar sig i olika sätt att skriva t. ex en titel framhölls.
Något som kan vara intressant att titta närmare på är NTNUs digitaliseringsprojekt där de vill presentera det inskannade materialet visuellt. De kunde inte nog poängtera vikten av en snabb, dedicerad server och att använda RDF och SPARQL. (Projektet ligger inte ute publikt ännu.)
The battle of the clouds
Dag två handlade mycket om nästa generations bibliotekssystem som ska finnas ”i molnet”. Paul Harvey från OCLC presenterade ”Web scale library management services (WMS)”. Ett kooperativt system för alla slags material som omfattar alla tänkbara bibliotekssystemsmoduler, om jag förstod det rätt. Det ska bygga på existerande OCLC-data och mjukvara, vara stensäkert hostat, feltolerant, snabbt, flexibelt, integrerbart och massivt skalbart.
Carl Grant från Ex Libris pratade om de fördelar som ett verkligt integrerat bibliotekssystem i molnet innebär. För biblioteken är det viktigt att kunna skräddarsy systemet och göra det tydligt för användare vad det egna bibliotekets unika värde är. Man behöver kunna konfigurera systemet, kontrollera och justera relevansrankingen. Han nämnde också att samarbete mellan leverantörer behövs, för att kunder smidigt ska kunna byta flytta mellan systemen.
Sedan kom representanten för bibliotekens verklighet, Anders Söderbäck från Stockholms UB, som höll en uppskattad presentation om vikten att vara medveten om vem som äger datat i ”molnet”. Licensfrågor är betydligt svårare än teknik! Han menade också att ett verkligt integrerat bibliotekssystem är en fjärran vision. I realiteten kommer vi även i framöver vara beroende av flera olika system som behöver kunna kommunicera med varandra.
Anders visade på två framtidsscenarier; en gyllene biblioteksvärld med öppen data, flexibel infrastruktur, tillgänglig kunskap och decentraliserad bibliografisk kontroll alternativt en dyster vision där vi är inlåsta i restriktiva avtal och marknaden monopoliserad av ett fåtal organisationer som kontrollerar informationsresurserna. Mest realistiskt är antagligen något mellanting.
Förmiddagen avslutades med en paneldiskussion om den molnbaserade biblioteksinfrastrukturen. Frågan om biblioteken verkligen vill dela sin data i alla lägen lyftes. Kommer alla bibliotek våga lita på säkerheten för att hantera låntagardata i de molnbaserade systemen? Vad vill vi dela? Förvärvsposter? Hur villiga är systemleverantörerna att göra det bibliografiska datat öppet, om biblioteken mot förmodan lyckas ingå avtal med förlagen? En annan viktig fråga är att definiera protokollen och standarder mer specifikt så att interoperabilitet mellan system från olika leverantörer fungerar smidigare än de gör idag.
I ett senare lightning talk poängterade Uwe Dierolf vid Karlsruhe Institute of Technology vikten av att att kunna pimpa sin katalog och personalisera den utifrån egna behov. Här behöver man ha järnkoll på vad man kan och får göra i sitt hostade system. Man behöver tänk efter och kräva sin rätt att kunna modifiera molnlösningen mycket och detta INNAN man skriver på kontraktet. Inte minst med tanke på framtida eventuella utvidgningar och integrering med andra system. Snabbhet och flexibilitet bör vara nyckelord, liksom att inte bara läsa utan verkligen förstå sitt serviceavtal och de kostnader det innebär. Att ha en strategi för att kunna lämna systemet är också viktigt.
Smått, stort och gott
• VIAF (Virtual International Authority File) är välkänd för katalogisatörer. Det arbetas med att förbättra sökgränssnittet (som redan nu är riktigt trevligt) integrera mer länkad data, fler namntyper och att även andra organisationer än bibliotek ska kunna bidra http://viaf.org/
• LCHS (Library of Congress Subject Headings) blir också alltmer visuell och rolig att söka i. http://id.loc.gov/search/
• Det helt digitala biblioteket vid Open University of Catalonia arbetar på att omdesigna sin webb. Utgångspunkten är att integrera det med studenternas dagliga miljö. Många intressanta tankar i presentationen. Följ utvecklingen på http://labs.biblioteca.uoc.edu/blog
• marcXImiL är ett verktyg för att jämföra liknande poster inom en samling eller mellan samlingar. http://marcXImiL.sourceforge.net
• Tiqr, ett sätt att autenticiera mobilapplikationer med QR-koder https://tiqr.org/
• ”Marc is dead” påstods det i en av arbetsgrupperna. LC tittar på vad som är värt att bevara i Marcformatet och på hur en övergång till ett nytt format ska kunna ske. http://www.loc.gov/marc/transition/
• Karen Coombs på OCLC experimenterar med flera olika sätt att visualisera biblioteksdata. Integrering med Google Maps; värmekartor för att visa frekvens; författartidslinje; ämnestidslinje (frekvens för ämnesord, när började t. ec begreppet Global warming förekomma); ämnestaggmoln; organisationsstruktur; klassning, materialtyp och bestånd (visualisering av vilken typ av material ett biblioteket har inom ett ämnesområde); volkabulärer som hierarkiska träd m.m. Mycket inspiration att hämta på http://www.oclc.org/developer/
Dagen innan den egentliga konferensen kunde man delta i en förkonferens. Jag ville få en bättre förståelse av vad länkad data egentligen är och mitt val föll därför på ”Your Website is your API – How to integrate your Library into the Web of Data using RDFa”. Under dagen fick vi lära oss hur man kan berika befintliga webbsidor med maskinläsbar kod. RDFa står för ”Resource Description Framework in attributes” och själva idén är att bädda in attributen direkt i XML-taggarna. Förutom att det är ganska enkelt och gör innehållet till maskinläsbar länkad data är det bra även ur sökoptimeringssynpunkt.
Jag testade att hämta källkod från vår egen webbsida med kontaktinformation och göra informationen i den till länkad data. Kollade sedan sidan i RDF distiller http://www.w3.org/2007/08/pyRdfa/ Det var lite knepigt, dels för att jag är nybörjare, dels för att koden var gjord i Roxens editor och innehåller en del andra taggar att förhålla sig till. Men det funkade!
Just kontaktuppgifter, öppettider och liknande kan vara extra tacksamt att göra maskinläsbart. Inte minst för att slippa underhålla lätt föränderliga uppgifter på andra ställen än den egna webbplatsen. Enklast vore givetvis om RDFa var integrerat i CMSen men än så länge behöver man gå in direkt i källkoden för att lägga till attributen (förutom i Drupal 7 ?).
För att få en permanent URI kan man registrera sig i MARC Organization Codes Database och få en ISIL (International Standard Identifier for Libraries and Related Organizations) http://www.loc.gov/marc/organizations/orgshome.html
Publiceringstjänsten arXiv.org har på många sätt gått i täten för att utveckla den vetenskapliga kommunikationen på internet. Fysikern Paul Ginsparg startade tjänsten redan 1991 och den är idag en viktig kommunikationsresurs för flera vetenskapsområden; framför allt inom fysik, astronomi och astrofysik samt matematik. Artiklarna publiceras som s k preprints (eller e-prints) och blir direkt tillgängliga för läsarna. Många preprint blir i ett senare skede granskade och antagna som tidskriftsartiklar. Årligen publiceras fler än 60 000 artiklar i arXiv och användarna gör över 30 miljoner nedladdningar.
Sedan tio år tillbaka har Cornell University Library tagit över ansvaret för att driva arXiv. För att säkra den långsiktiga driften och för att kunna vidareutveckla tjänsten har Cornell University Library tagit fram en supportmodell riktad till de lärosäten som är de främsta användarna av arXiv (dvs där användarna gör flest nedladdningar från databasen). Under fjolåret fick man på detta sätt in över 320 000 USD, från 10 olika länder och från över 100 olika organisationer. Enligt den statistik över nedladdningar från arXiv som Cornell presenterat gör Chalmers forskare och studenter över 27 000 nedladdningar årligen. Från och med 2011 stöttar Chalmers bibliotek arXiv genom ett aktivt medlemskap enligt den supportmodell som Cornell University Library lanserat.
Om du som Chalmers-forskare har synpunkter på arXiv – antingen som författare eller som läsare – tar biblioteket gärna emot dessa.
Årets UKSG-konferens hölls i Harrogate, North Yorkshire, 4-6 April. Från Chalmers bibliotek deltog Rose-Marie Boström och Lars-Håkan Herbertsson.
UKSG beskriver sin verksamhet så här:
“UKSG exists to connect the information community and encourage the exchange of ideas on scholarly communication. It is the only organisation spanning the wide range of interests and activities across the scholarly information community of librarians, publishers, intermediaries and technology vendors. “
Innehållet på konferensen brukar vara en allmän avstämning av aktuella frågor relaterade till vetenskaplig kommunikation, och även frågor inom akademiska biblioteksvärlden i största allmänhet. Det kan gälla områden som sociala medier, open access, nya former för publicering, parallellpublicering, omvärldsförändringar och hur det inverkar på biblioteken. Man kan inte säga att innehållet ligger i framkant, att man presenterar det allra nyaste. Värdet ligger istället i att man får en uppdatering på vad som är på gång.
UKSG fungerar som en mötesplats mellan bibliotek, förlag och vendors. Inslaget av deltagande svenskar brukar vara stort.
Föredragen var indelade i 6 sessioner med breda teman.
1. Future Communicatons
2. New approaches to research
3. Retinking ‘content’
4. Strategic directions in a constrained world
5. Improving access
6. Anticipating and managing change
Det var också ett stort antal mindre sessioner (breakout sessions) med specifika teman. Vi täckte upp:
The journal Usage Factor (ett alternativ till Impact Factor)
Driving usage-what are publishers and librarians doing to promote usage
Refurbishing the digital library – how far can users define our e-strategy?
DataCite (om att citera data, inte bara text)
Open access repositories (lessons learned from Univ Glasgow)
Turn off that phone! Mobile technologies in the library
The price of online investment (för förlag)
Unified Resource Management (om nästa generations ERM system från Exlibris: ALMA)
Utöver föredragen som för det mesta var allmänt intressanta hade vi möjlighet att mingla med förlag, agenter och vendors. Vi träffade EBSCO, LM, IOP, AGU, Emerald, BioMedCentral, Proquest, ExLibris, Science, Future Science, SAGE, Cambridge Univ Press, SPIE…
Ett litet axplock av föredragen (samtliga från sessionen New approaches to research):
CameronNeylon (Science and Technology Facilities Council), som är biofysiker, gjorde en intressant betraktelse över utvecklingen de sista 15-20 åren. När han började som doktorand år 1994 rekommenderade hans handledare honom att tillbringa en halv dag i veckan i biblioteket för att läsa (”scanna”) tidskrifter och innehållsförteckningar. Fem år senare när avhandlingen var färdig hade Google kommit. Detta gjorde honom till del av den sista generationen som minns biblioteket som en plats dit man går för att ”accessa” information. Den sista generationen som tänker på tidskrifter som pappers-objekt. Idag: ” The idea of physically searching a paper index is almost a joke”.
Neylons budskap var att vi behöver öppna system för utbyte av forskning. Bort med gatekeeper- filter. Öppna system! Användaren kan filtrera själv. Misslyckade experiment har också sin publik och sitt värde (för vetenskapens skull), men i nuvarande publiceringsmodell publiceras det inte.
“We need to connect people with people so they can build discovery systems. Enable, don’t block. Build platforms not destinations, sell (provide) services not content. The content game is dead. Forget about filtering and control and enable discovery.”
“The gatekeeper was needed in a broadcast world – expensive printing and distribution needed centralising. Decisions needed to be made about what to publish and what to collect. The current flood of information is the ”central research opportunity of our age”
Neylon avslutade med ett provokativt påstående att det inte finns några bevis för att referee-systemet åstadkommer något bra för vetenskapen.
Man kan fundera över vilken roll bibliotekarierna och förlagen har i hans modell. Om ”content” försvinner och allt blir ett ”flöde” där användaren själv sätter filtrerna. Knappas någon roll alls?
Philip E Bourne (Univ California, San Diego) var inne på liknande tankegångar om tillgängliggörande av ”vägen till forskningsresultat” snarare än att publicera slutresultat (papers), men i motsats till Neylon betraktade han inte förlag som något onödigt:
“as a scientist I want an interaction with a publisher that does not begin when the scientific process ends but begins at the beginning of the scientific process itself”
Enligt Bourne kan man dela in forskningen (och indirekt tillkomsten av ett paper) i fyra steg: Idéer, Experiment, Datainsamling, Slutsatser. I nuvarande publiceringsmodell kommer förlagen in i 4:e steget, men de borde komma in vid 3:e i stället, alltså data-steget. Digital publicering skulle kunna vara mycket mer än bara pdf. Det finns dock steg i denna riktning: ” For example in Elsevier’s ScienceDirect (and some others too) you can click on a figure/image and move it around and manipulate it – the application is integrated on the platform because a publisher and a data provider has cooperated. But this is just the beginning; when you click on the diagram in the article, you’re getting some data back but it’s generic and it might not be organised in the way that you want. It’s generic – the figure is being viewed separately from the article text and related data – now you have to figure out what that metadata means to the article. So this is a good step but it’s not capturing all of the knowledge that you might want. It needs more cooperation, more open and interactive apps.”
Både Bourne och Neylon var förespråkare av sociala medier vid tillgängliggörande av forskning. Intressant var det då att höra det tredje bidraget i samma session som gav en annan bild. Bill Russell (Emerald), redogjorde för en brittisk survey över forskares användning av sociala medier. Forskare är i allmänhet inte intresserade av twitter, Facebook, och social tagging. De mest populära sociala verktygen var Skype, Wikipedia och Google Docs. Man ser i allmänhet inget samband att användandet av sociala medier skulle kunna höja en forskares impact. Överraskande nog visade också studien att det inte skiljer mellan unga och äldre i detta avseende.
Varför har Chalmers antagit en Open Access-policy?
För att säkerställa största möjliga spridning av Chalmers vetenskapliga resultat. Det är också i enlighet med de krav om Open Access som allt fler forskningsfinansiärer ställer, bl.a. Vetenskapsrådet och Formas i Sverige.
Vad omfattas av policyn?
All forskning som Chalmers forskare publicerar, men böcker, bokkapitel och patent är undantagna.
Från när gäller policyn?
Policyn trädde ikraft den 1:e januari 2010 och gäller de publikationer för vilka tecknande av publiceringsavtal/copyright-överlåtande skett efter införandedatum.
Tillåten fördröjning?
Publikationer måste göras fritt tillgängliga senast 6 månader efter publicering (12 månader i undantagsfall).
Parallellpublicering i CPL
Chalmers Open Access-policy är i huvudsak inriktad på så kallad parallellpublicering, vilket innebär att en kopia av vetenskapliga artiklar skall publiceras i fulltext i Chalmers publikationsdatabas – CPL. En majoritet av de förlag som finns registrerade i databasen SHERPA /RoMEO tillåter detta in någon form. Oftast är det författarens sista, godkända och rättade manuskript som får läggas ut. Men ett antal förlag, bland andra IEEE tillåter att man använder förlagets PDF-version av artikeln.
Jag har deponerat min artikel i ett annat öppet arkiv – räcker det?
Nej, kravet på deponering i CPL föreligger oavsett om arbetet finns deponerat i ett annat öppet arkiv. Detta eftersom Chalmers inte kan garantera tillgängligheten i andra öppna arkiv.
Jag har publicerat min artikel i en OA-tidskrift – räcker det?
Nej, kravet på deponering i CPL föreligger oavsett om arbetet finns i en OA-tidskrift.
Vad vinner jag som författare på detta?
Ökad synlighet och förhoppningsvis ökad citering och genomslagskraft.
Behöver jag tillåtelse från medförfattare?
Förlagens copyrightavtal inkluderar normalt samtliga författare till en artikel. Om avtalet tillåter författare att deponera en kopia av artikeln i ett öppet arkiv så kan du göra det även om det finns fler författare.
Kan jag få dispens?
Dispens kan ges undantagsvis. Det måste i så fall finnas prestigemässiga skäl att publicera ett specifikt vetenskapligt arbete i en tidskrift som inte medger parallellpublicering. Dispensbegäran skall vara skriftlig och ställas till prorektor
Postprint eller preprint?
När man talar om Open Access genom parallellpublicering menar man i första hand artiklar som har genomgått peer review och publicerats i en vetenskaplig tidskrift, s.k. postprints. Ett postprint definieras som en artikel som antagits för publicering och genomgått sakkunnigbedömning, samt att eventuella ändringar föranledda av granskningen är införda i artikeln. Ett preprint å andra sidan är en artikel som ännu inte antagits eller genomgått sakkunnigbedömning. Om ett förlag endast godkänner att preprints parallellpubliceras så är detta godtagbart enligt Chalmers policy även om ett postprint är att föredra.
Författarversion eller förlagsversion?
Utöver distinktionen mellan postprint och preprint så är det viktigt att även skilja på två varianter av postprints, nämligen förlagets publicerade pdf-fil och författarens slutliga godkända manuskript. Förlagets pdf är helt enkelt den pdf som publicerats i tidskriften. Författarens sista version är i idealfallet innehållsligt identisk, men oformaterad och innehåller inte tidskriftens paginering eller logga. De flesta större förlag tillåter idag endast parallellpublicering av just författarversionen och inte förlagets pdf.
När en publicerad artikel deponeras i ett öppet arkiv, är det viktigt att bibliografiska uppgifter fylls i korrekt och att man även länkar till den officiella publicerade versionen av artikeln (det är något som nästan alla förlag kräver). När fulltexten dessutom är en författarversion är det högst rekommendabelt att lägga till ett standardiserat försättsblad som på ett tydligt sätt anger referensen och att versionen är sakkunnigbedömd (vilket nästan alla förlag också kräver). Försättsbladet läggs in som första sidan i pdf-filen.
Försättsblad
Exempel på hur man kan formulera ett sådant försättsblad för en vetenskaplig artikel:
This is an author produced version of a paper published in Journal of example science. This paper has been peer-reviewed but does not include the final publisher proof-corrections or journal pagination. Citation for the published paper: Andersson, A., “Example of a paper”, Journal of example science, 2007, volume 5, issue 5, pp. 5-10. URL to article at publisher’s site: http://dx.doi.org/13234567889 Access to the published version may require journal subscription. Published with permission from: Förlagsnamn
För att försöka besvara den frågan har vi studerat artikelproduktion och citeringsmått efter försteförfattarens ålder. Undersökningen bygger på tidskriftsartiklar i Web of Science publicerade 2005-2007, och för att få tillräckliga volymer har vi använt tioårsintervall på författarna (25-34 år, 35-44 etc). Endast artiklar med försteförfattare från Chalmers har använts. C:a 60% av alla artiklar med Chalmersadress har försteförfattare härifrån. Det fältnormerade citeringsmåttet Cf har beräknats både med och utan självciteringar
Resultaten visar att citeringsmåtten sjunker med ökad ålder hos författaren.
Vid Aalto-universitetens forskningsutvärderingar (Striving for Excellence) använde man följande nivågruppering :
Cf
<0,60
Signifikant under internat. medelnivå
0,60-1,20
Internationell medelnivå
>1,20
Signifikant över internationell medelnivå
Utifrån denna gruppering skulle alltså forskarna mellan 25-34 år på Chalmers prestera signifikant över internationell medelnivå.
Det finns givetvis flera förklaringar till varför det ser ut så här, men en Intressant följdfråga är hur ålderstruktur påverkar eventuell universitetsranking som bland annat baseras på bibliometrisk data. Skulle ett ökat tillskott av doktorander och yngre forskare påverka detta på ett positivt sätt? Ranking är ju något som diskuteras livligt på de flesta lärosäten nuförtiden och man letar ständigt efter sätt att klättra på listorna.