Vi har byggt ett nytt databassök och tänkte dela med oss av våra erfarenheter och tankar. Välkommen att testa det nya databassöket (beta) det nya databassöket (live 20150922).

Vi gjorde användarintervjuer under våren med masterstudenter och doktorander. Gemensamt var att de inte använt sökverktyget och att de önskade att de hade träffat på det tidigare. Databaser var ju bra resurser att söka information i!
Vårt allra tydligaste och viktigaste resultat var att våra användare vill ha mer och tydligare hjälp att välja! När sökningen är gjord och man sitter där med sin träfflista, vad gör man då? En del försökte läsa beskrivningar men blev inte så mycket klokare av det. Alla (!) efterfrågade någon slags indikator om vilken som var ”störst” eller ”bäst”. När det inte fanns tenderade de att välja välbekanta databaser, eller ingen alls. Ett exempel var en användare som var ute efter en tidskriftsartikel, klickade på sitt ämne och fick fram en lång träfflista. Där gick hen vidare till den tidigare använda e-boksplattformen Books24x7, väl medveten om att den endast innehåller böcker.
När testerna gjordes hade vi en mängd ämnesövergripande databaser som var uppmärkta med ”Multidisciplinary”, vilket låg som ett av många ämnen att klicka på. Våra farhågor om att det var ett svårförstått begrepp och ointressant att välja, besannades. Alla ville välja sitt eget ämnesområde. Såklart. Helst så smalt avgränsat som möjligt. Vi kunde dock se att de ”smala” ämnesorden, som härrör från Libris bibliografiska post, ställde till det. När användaren klickade på ett sådant missade de en hel del relevanta databaser eftersom alla inte tilldelats just detta ämnesord. T.ex leddes de att tro att det bara fanns enstaka databaser som innehöll ämnet ”Biotechnology” när det i själva verket var många. Särskilt missades de breda databaserna, det går ju inte att sätta hela världens alla ämnesord på t.ex Web of Science…
För att bilda sig en uppfattning om databasen ville de ha en kort, koncis och neutral beskrivning, helst där det framgår vilka ämnen som den omfattar och vilken typ av material som finns där. I dagens databassök måste man klicka på en flik för att se vilken typ av innehåll databasen har. Det borde framgå tydligare, tyckte våra testpersoner.
Våra tips om inloggningar och annan nyttig information, som vi lagt under under en flik, var det ingen som såg. Vi noterade även motsägelsen att våra testpersoner tyckte att ämnesingången var viktigast, medan statistiken visar att A-Ö används mest.
Med det nya databassöket vill vi fokusera på:
- Hjälp att snabbt hitta ”det bästa”, för de som inte vet var de ska börja
- Ett mer lättanvänt gränssnitt
- Att tydligare visa databasernas typ av innehåll
- Att kunna kombinera ämnen, typer och fritt tillgängliga databaser
- Att synliggöra breda databaser utan att ”skräpa ner” träfflistan
- Relevant ordning av träfflistan
- Att ge kontextuell information om olika innehållstyper
- Att ge användarna rätt länk till våra databaser när de söker upp dem via Google och andra sökmotorer
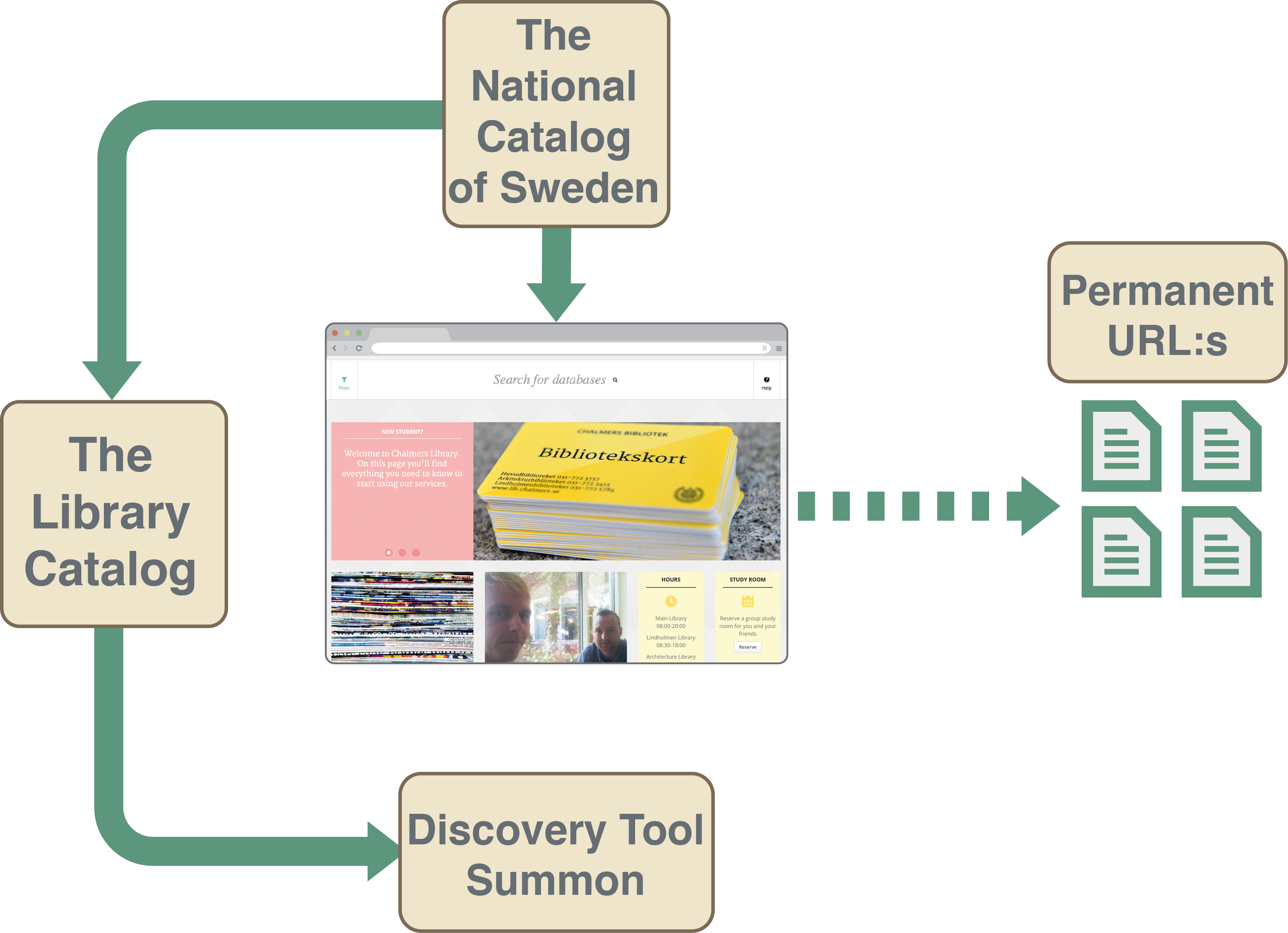 Vårt nuvarande databassök
Vårt nuvarande databassök
Det nuvarande databassöket kom till strax efter att vi lanserade en ny bibliotekswebb våren 2013. Vi ville kunna söka databaser via den vanliga sökrutan, både som en egen tjänst och genom discoveryverktyget. Vi ville administrera posterna på ett ställe (i Libris), och återvinna dem i databassöket, discoveryverktyget (Summon), bibliotekskatalogen (Chans), och som permanenta länkar i ämnesguider (LibGuides), på andra webbsidor och i Summons rekommenderade länkar (sk. Best bets). För att göra detta valde vi att katalogisera i Libris med fokus på beståndspostena, och använda dess API.
Om arbetet med det nuvarande databassöket kan du läsa i en artikel vi skrev till Charlestonkonferensen 2014, i samband med en poster-presentation. Trots att detta innebär vissa begränsningar och är lite krångligare att katalogisera, har vi valt att behålla detta flöde eftersom vinsterna med poståteranvändning är många. All viktig info, förutom titeluppgifter, finns i beståndsposten eftersom vi kan ha full kontroll över den.
Vad är en databas, och vilka skall man ta med?
Vad menar vi med databas? Det har vi nog inte riktigt klart för oss fortfarande, har ingen exakt princip eller definition. Man skulle kunna säga att listan har kommit att bestå av olika e-resurser som varken är böcker eller tidskrifter, men inte heller det stämmer riktigt. Antagligen känner många bibliotekarier igen sig i detta. Det är också lätt hänt att fria resurser som är ”bra att ha” blir liggande i listan, men sådana kan med tid bli inaktuella eller mindre användbara.
Bibliografiska databaser känns självklart att ta med. Databaser över patent och standarder är med. Bild-databaser, affärsdatabaser, juridisk information, statistik, kartor… Vi har diskuterat encyklopedier och handböcker en del. Dessa är ju ”egentligen” böcker och finns att hitta i Summon. Samtidigt finns det några riktigt viktiga och stora som vi inte vill att användarna skall missa, så dem har vi tagit med. Det blir naturligtvis subjektivt.
Vi vill gärna visa fram OA-resurser, och vi har därför med många preprint-arkiv, men där är utmaningen att selektera och försöka undvika alltför mycket överlappning.

Marie Kennedy, http://orgmonkey.net/?p=1325#sthash.Ic4SPgSx.KkGgelaY
Typer, ämne och ordningen i träfflistan
Benämningar för olika typer av databaser har vi brottats en del med. Termerna måste säga någonting för slutanvändaren. Vi har utgått från innehåll, vad för typ av material man kan hitta i databasen, snarare än vilken typ av databas det är. Vi säger ”Articles”, inte ”Bibliografic database”. Vi hoppas detta är lättare att förstå. Ett undantag som vi inte vet hur vi skall hantera är ”Publishers”. Detta är ju ingen typ av material. Vi sätter denna typ på förlagsportaler, som vi har med i listan för att visa användarna var man kan teckna upp sig för alerts.
Vi har förkastat och lagt till typer allt eftersom. En vi gjort oss av med är ”Facts”. Den använde vi för databaser där man kunde hitta just… fakta…snarare än forskning. Vi slängde in smått och gott där, sinsemellan helt olika databaser, och det blev en konstig blandning i träfflistan. En tumregel kan vara att om man absolut inte kan förklara vad man menar med en benämning, så skall kan man nog inte använda den.
Vi har använt breda ämnesområden, delvis återspeglande Chalmers forskningsfält. Eftersom mängden databaser är relativt liten, och många av databaserna är breda så kan vi inte ha en finfördelad ämnesindelning. Vi skulle i så fall bli tvungna att sätta massor av ämnesord på flertalet databaser, och det blir lite poänglöst. I många fall har vi slagit ihop flera områden till ett.
Ämnesorden från Libris bibliografiska poster syns inte längre i det nya databassöket eftersom har visat sig vara mer till förvirring än till nytta. Vi har inte heller tid att ge alla databaser alla ämnesor de borde ha. Däremot finns fortfarande med i sökindexet.
Vi har hela tiden brottats med dilemmat om hur vi ska tilldela ämnen och haft många och långa diskussioner om det i utvecklingsgruppen. Ska alla som innehåller något som helst material inom ämnet, märkas med det? Eller ska det visa att det är en databas som är vettig att söka information inom ämnet? T.ex en generell ordbok, ska den få alla ämnen? Eller inget? Ska Statistiska Centralbyrån komma med i alla sökningar på ett ämne? Eller bara om man väljer typen statistik? Vi har tagit bort benämningen Multidisciplinary som vi tidigare använde för databaser som innhåller många ämnen, men valt att fortsätta med tanken att inte sätta ämnen på ”ämnesospecifika” databaser som t.ex ordböcker. På så sätt tänker vi att ämnessökningar inte skräpas ner av allför många databaser som inte är direkt ämnesrelevanta. Samtidigt leds kanske en person som väljer t.ex Mathematics att tro, att det inte finns några ordböcker inom ämnet, andra än Brittanica och NE som visas pga av att de fått ämne inom typen uppslagsverk. Vi är fortfarande inte helt i hamn här.
De definitioner som vi nu använder är att databasen för en Chalmersanvändare ska vara:
- Relevant för att söka information inom ett visst ämne. (Om den inte är det tilldelas den inget ämne.)
- Relevant för att söka material av en viss innehållstyp. (Alla ska ha minst en innehållstyp.)
Vi har haft en del huvudbry under utvecklingsarbetet med att få ihop en bra lösning för ordningen i träfflistan, nu när vi skall ge möjlighet att kombinera ämne och typ. Det bottnar i att vi velat åstadkomma olika saker samtidigt, dels måste ju användaren få styra själv över träfflistan genom sina val, men dels vill vi ju lyfta fram ”de bästa”. Som det såg ut blev inte alla kombinationer bra, ”fel” databaser lyftes fram och andra riskerades att inte hittas.
Särskilt innehållstypen ”Patent” gav upphov till långa diskussioner. De hörde till de databaser som från början inte hade något ämne alls. Om då ändå användaren skulle kombinera ett ämne med ”Patent” så skulle inte de databaser som verkligen är bra på patent komma högt i träfflistan. Istället skulle någon annan databas som främst innehåller annat material, men även innehåller patent, komma högre. En lösning vi tänkte var att omöjliggöra kombination av vissa typer med ämne, men när vi vred och vände på det så blev det annat som inte var bra. Vi har micklat med speciallösningar, ha olika logik för olika typer, att låta de generella databaserna alltid följa med oavsett vilket ämne man valt, osv.
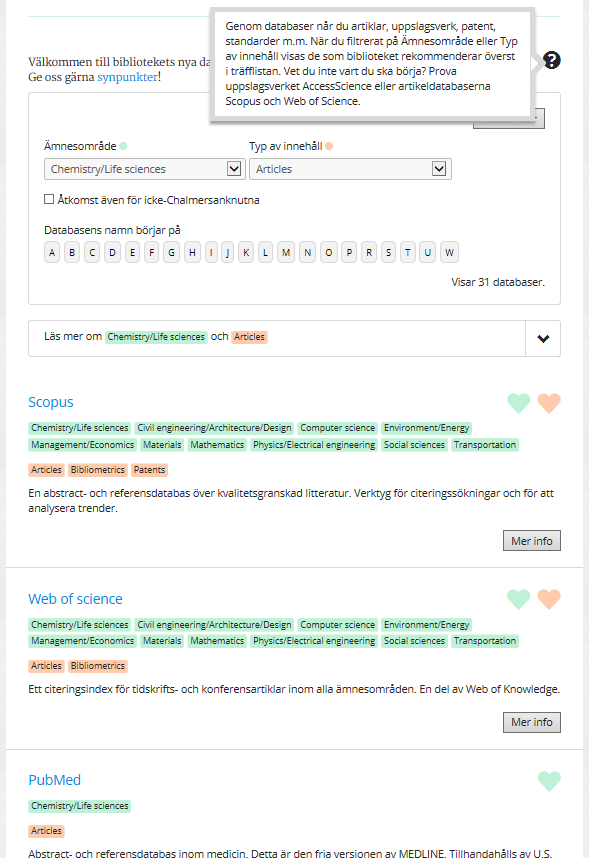 Rekommenderade databaser – en hjärtesak
Rekommenderade databaser – en hjärtesak
Vi har valt ut ”de bästa” databaserna inom varje typ och ämne, dvs de som är bra att börja söka information i, för såväl grundstudenter som forskare. Vi rekommenderar cirka tre till fem databaser inom varje ämne och typ. Vissa databaser, som Scopus och Web of Science, har fått massor av rekommendationer pga av att vi vill framhålla dem inom alla ämnen.
Vi har använt ikoner i form av hjärtan i två olika färger, samma som för de utskrivna ämnena och typerna i träfflistan. Vissa farhågor finns att de skall uppfattas som favoriter som man själv kan lägga till, eller något ”socialt”, att många har ”gillat” dessa databaser. Men vi är väldigt förtjusta i våra hjärtan så nu testar vi det!
Tekniskt sett är träfflistans ranking logisk och objektiv: Först visas de med rekommendationer på både ämne och typ, sedan de med rekommendation inom typ, sedan rekommendationer inom ämne och sist de som inte är rekommenderade.
I själva verket är databassöket och ordningen av träfflistan subjektiv från början till slut, det är lika bra att erkänna det. För det första väljer vi vilka databaser vi ska ta med över huvud taget. För det andra väljer vi vilka som ska tilldelas särskilda ämnen och typer av innehåll (det finns alltid gränsfall) vilket styr om de ska komma med vid filtreringar eller inte. För det tredje väljer vi vilka som ska få rekommendationer. Dessutom tipsar vi om några utvalda, i hjälptexten vid filterrutan, för de som inte alls vet var de ska börja.
Beskrivande texter
Det är lätt att ta den enkla vägen och kopiera någon text från leverantörens egen beskrivning. Följden blir att stilen på beskrivningarna får olika karaktär mellan de olika databaserna, ingen rak linje. Leverantörens egen beskrivning är ofta ”säljande” och detta vill vi undvika. Det är också lätt att rabbla upp siffror, såsom ”databasen indexerar x antal tidskrifter” och så vidare. Detta kräver ständig uppdatering, och säger kanske inte så mycket för slutanvändaren, så vi har tagit bort allt sådant.
För träfflistan har vi försökt göra korta, neutrala texter som kompletterar ämne- och typindelningen. När man klickar sig vidare till nästa nivå (”Mer info”) har vi däremot tillåtit oss att skriva mer subjektivt och utförligt och t.ex ge tips om inloggningar när vi tycker att det behövs. Här kan vi även länka till t.ex tutorials. Här har vi också tänkt förklara varför vi har valt att rekommendera just denna databas. Vi använder beståndspostens 500-fält och har lagt in html där, trots att det ser lite tokigt ut i Libris detaljerade vy.
 Googlingsbara Mer info-sidor om varje databas
Googlingsbara Mer info-sidor om varje databas
Förutom utökade beskrivningar ligger här permanenta länkar direkt till databasen för den som vill bokmärka. Vi har gjort dessa i form av re-directlänkar, som hämtar urlen från katalagposten i vår primärkälla Libris. För en rekommenderad databas syns här exakt vilka ämnen och typer den är rekommenderad inom. Här ligger också en länk till användningsvillkor från electronic resource management systemet.
För att så många sökmotorer som möjligt ska hitta sidorna har vi skapat en skript-fri sida som de kan indexera. Varje Mer info-sida har sin egen URL. Vi hoppas att sökmotorerna ska känna igen en användare som ofta använder Chalmers så att när hen googlar på t.ex Scopus så ska hen hamna på vår Scopus-sida.
 Mervärde med kontextuell information
Mervärde med kontextuell information
Många användare är obekanta med de olika typerna av e-resurser. Vad menas med en artikel i ett akademiskt sammanhang? Hur hittar jag egentligen e-böcker, och går det beställa en titel om jag inte hittar? Vad är en standard, och kan jag få tag i fulltext? Det finns mycket vi vill tala om, inte för vår egen skull utan för att hjälpa användaren.
När ett filter är valt dyker det upp en möjlighet att läsa mer om just denna typ av innehåll eller det valda ämnet. För ämnen tipsar vi om relaterade ämnesguider (LibGuides) som därmed får ökad exponering. Det ska bli spännande att se om våra användare fäller ut den extra informationen.
Som en sommargåva lägger vi nu ut det nya databassöket som en beta, bakom det befintliga. Exakt vilka databaser som ska rekommenderas är inte spikat och det saknas en hel del utökade beskrivningar. Vi hoppas få in mycket synpunkter och ersätta det nuvarande databassöket så snart det känns moget. Men allra viktigast är nog, som kloka medarbetare påpekat, att se till att användarna hittar våra databaser. De är ju bra resurser att söka information i!
/Lars-Håkan Herbertsson & Marie Widigson
Scrum-teamet har bestått av systemutvecklare Lars Andersson, Lari Kovanen och ovan nämnda bibliotekarier









{kind=link}